Introduction
The kernel heap is a lot more complicated and chaotic than userspace heap. Let’s break it down one step at a time. Here are some things to keep in mind before going forward:
kmallocandkfreeare used to allocate and free memory respectively. they are the most commonly used heap API functions in the kernel codebase- When memory is requested through
kmalloc, it is taken from aslab, which in turn consists ofpages pagesare continous memory units aligned by0x1000, on x86 atleastpagesare contiguous in virtual memory but need not be physically contiguousslabsare of various orders starting from 0. Aslabof order 0, consists of 20 = 1page, a slab of order 1, consists of 21 = 2pages.- There are separate allocators for
pagesandslabs - There is only one page allocator in the kernel, known as the
Binary Buddy Allocator. It exposes certain page allocation API such asalloc_pages,__free_pages - There are 3
slaballocators:SLOB,SLABandSLUB. They use the page allocator for obtaining slabs. They exposekmallocandkfreeAPIs
Let’s now look at each of these allocators one by one and how it all adds up. At the end of each section, there will be some links for more info on the same. They are references I used or came across while learning about the kernel heap.
SLOB
Stands for Simple List of Blocks. This slab allocator is typically used in embedded systems or machines where memory is very limited. This allocator has been deprecated since v6.2. Some features of SLOB are:
- Implemented through less code since its simpler that other allocators
- It is memory efficient, however doesn’t scale and suffers from fragmentation
- Stores the freelist in the object itself
- Has multiple freelists based on size namely: small, medium and large
- If no memory is available in the freelist, extends heap using page allocator
- Uses K&R style allocation (Section 8.7, The C Programming Language)
LWN Article on SLOB Paper on SLOB exploitation
Before delving into SLAB and SLUB allocators, we have to first understand kmalloc-caches
kmalloc-caches
kmalloc-caches are “isolated” groups of slabs that are used to allocate memory of a particular size or for allocating specific objects. I put isolated in quotes since it is not always true. More about that in the upcoming sections. Caches are often initialized with some empty slabs to speed up allocations. By default there are a lot of caches that are created for objects of various sizes and types. Some of them being:
- kmalloc-32
- kmalloc-192
- kmalloc-1k
- kmalloc-4k
- files_cache
- inode_cache
The caches starting with “kmalloc” are called as general purpose caches. By default an allocation will end up in one of those caches depending on size requested. For example a request of size 32,
ends up in kmalloc-32, anything above that will be allocated in kmalloc-64 which is the next cache. There are certain caches that are reserved for objects of a specific type, such as files_cache for struct file and inode_cache for struct inode_data. You can get the slabs on your local machine by running sudo cat /proc/slabinfo in your shell.
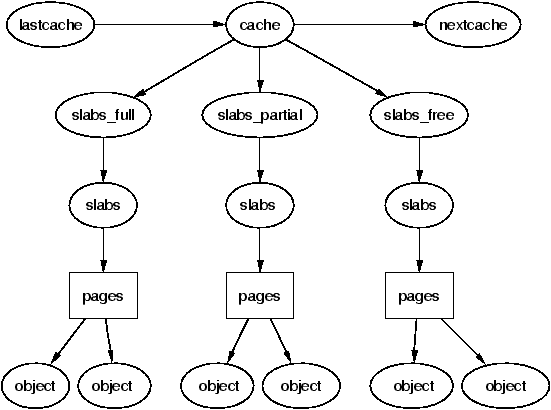
Each cpu (hardware thread) contains its own linked list of caches. This is the reason why you might see exploits setting affinity to a particular cpu. Each cache contains 3 more linked lists, namely:
slabs_full: contains slabs that are completely full (no memory left)slabs_partial: contains slabs that are partially full (some memory available)slabs_free: contains slabs that are completely empty (can be re-used or returned to page allocator)
+-----------+ +-------+ +-----------+
| lastcache | ----------------> | cache | ----------------> | nextcache |
+-----------+ +-------+ +-----------+
/ | \
_______________/ | \_________________
/ | \
/ | \
/ | \
+------------+ +---------------+ +------------+
| slabs_full | | slabs_partial | | slabs_free |
+------------+ +---------------+ +------------+
| | |
| | |
v v v
+-------+ +-------+ +-------+
| slabs | | slabs | | slabs |
+-------+ +-------+ +-------+
| | |
| | |
v v v
+-------+ +-------+ +-------+
| pages | | pages | | pages |
+-------+ +-------+ +-------+
/ \ / \ / \
/ \ / \ / \
/ \ / \ / \
+-----+ +-----+ +-----+ +-----+ +-----+ +-----+
| obj | | obj | | obj | | obj | | obj | | obj |
+-----+ +-----+ +-----+ +-----+ +-----+ +-----+
{kind=link}
This is the core mechanism used in SLAB and SLUB allocators. This leads to lesser fragmentation and scales well with more memory. Since the slab allocator holds onto some empty slabs, the allocation is fast and doesn’t always have to fallback on the page allocator.
Some API functions
kmalloc_cache_create()- Create a new cache for an object and add it to the global list of cacheskmalloc_cache_destroy()- Remove cache from global list of caches and frees slabs held by cachekmem_cache_alloc()- Allocates memory from a given cachekmem_cache_free()- Frees memory back to the cache
SLAB
Note: slab is a structure consisting of page(s) whereas, SLAB is a slab allocator
SLAB allocator is the first allocator to implement caching through kmalloc-caches. It speeds up (de)allocation of frequently used objects. The path for allocation looks something like:
- Traverse the current cpu’s cache list and find required cache
- Search the partial slabs list and get the first one
- if no slab is found in partial list, search free list
- if no slab is found in free list, then allocate a slab and add it to the free list
- Finds first free “slot” in the slab and returns that
- Marks the “slot” as used
Although the SLAB allocator increased performance and reduced fragmentation, it had some pitfalls. For systems with a large number of cpus, there exists queues per node per cpu. In such cases, the allocator uses up a lot of memory on startup.
Paper on SLAB allocator Kernel docs on SLAB allocator
SLUB
SLUB was designed as a drop-in replacement to the SLAB allocator. It simplified the implementation, getting rid of complex queues and metadata. Another major change is that the object freelist is stored inline, in the freed objects itself. SLUB also added support for merging slabs, to reduce memory overhead. This is done implicitly. Objects of similar sizes are cached together unless explicitly specified otherwise. This is known as cache aliasing, where a cache, actually uses the general purpose cache to back allocations. Other than these I can’t think of any other major changes between SLAB and SLUB from an exploitation point of view.
You can find cache aliases by running ls -l /sys/kernel/slab/. The symlinks indicate aliasing. Every entry with the same symlink destination, indicate that they are backed by the same cache.
kmalloc() is now just a wrapper to kmem_cache_alloc_trace(). Similarly kfree() uses kmem_cache_free() internally. The size requested is used to determine which general purpose cache can be used to allocate it. kmem_cache_alloc() should be used when requesting allocation from a particular cache.
Presentation on SLAB and SLUB Presentation on SLOB, SLAB and SLUB Structures in SLUB allocator
Buddy allocator
The buddy allocator a.k.a the binary buddy allocator, or simply the page allocator, takes on the role of allocating physical pages. It’s API is used by the slab allocators and vmalloc() internally. It is the most low level memory allocator. The return value is usually struct *page or the starting virtual address of the pages. Every physical page in use has an associated struct page, to keep track of metadata. Multiple pages part of the same struct page.
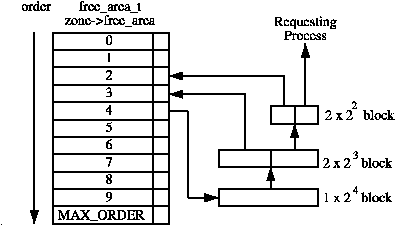
The allocation is based on order specified, similar to slab order, where order n gets you 2n pages. On freeing pages, it doesn’t destroy the page table entry but rather keeps the page for future allocations.
- Pages of same order are grouped into pairs, known as buddies
- When a block is freed, its buddy is checked. If the buddy has already been freed, then they are merged into a block of higher order
- The merging is attempted continously until block of
MAX_ORDERis reached - During allocation, when block of requested order is present, it is returned as is
- If not, a block of higher order is split iteratively until required order is reached. The remaining blocks from splitting, are added to the freelist
Allocating pages of order 1, when there are only pages of order 3 available:
order +=================+ Requesting <--+
| | 0 | process |
| +=================+ |
| | 1 |<-------------------+ |
| +=================+ | |
| | 2 |<---------+ +-----+ +-----+
| +=================+ | | 2^1 |<-+->| 2^1 |
| | 3 |--+ | +-----+ | +-----+
| +=================+ | +---------+ +---------+
| | . | | | 2^2 |<-+->| 2^2 |
| | . | | +---------+ | +---------+
| | . | | +-------------------+
| +=================+ +---->| 2^3 block |
| | MAX_ORDER | +-------------------+
v +=================+
{kind=link}
Some API functions
alloc_pages()- Allocates 2order number of pages and returns astruct pageget_free_page()- Allocates a single page, zeroes it and returns virtual address__free_pages()- Free 2order number of pages from givenstruct pagefree_page()- Free a page from the given virtual address
Kernel docs for buddy allocator Paper on buddy allocator
Exploitation primitives & techniques
Heap overflow
This primitive allows overwriting neighboring objects in a slab. Usually in such cases, we aim to get an object with function pointers or pointers in general, in hopes of overwriting them for stronger primitives such as rip control or arbitrary r/w.
Use after free
This can also be caused by an incorrect free primitive. This primitive allows us to hold a reference to a freed object. Allocating a different object in the same cache, allows us to cause type confusion. This is because we have 2 references to the same memory but through different contexts. Use the type confusion to control some member in the object and build stronger primitives from there.
Freelist poisoning
This technique can be used to hijack the object freelist in the SLUB allocator since it stores the freelist inline. This technique is partially mitigated through CONFIG_SLAB_FREELIST_HARDENED, although it can be bypassed. More about that in the upcoming sections. This technique allows allocation of arbitrary kernel memory.
Spray and pray
Heap sprays are a common technique used to increase exploit reliability. It just means spamming a lot of allocations of a particular object to counteract randomness caused by mitigations and system noise (allocations beyond our control). In some cases, the spray has to be controlled to achieve maximum reliability.
Cross-cache
This is a somewhat recent technique where vulnerable objects can overflow onto objects in another cache, or UAF objects can be allocated in a different cache. This requires careful manipulation of the slab (and page) allocator. Essentially, we cause an entire slab containing our vulnerable object to be freed and re-used by another cache. When the cross-cache is to a cache of different order, it requires manipulation of the page allocator as well.
Some hardening features
CONFIG_SLAB_FREELIST_RANDOM
This config option in the kernel randomizes the order of the slab freelist at runtime. The order of allocation in the slab is non-deterministic. Exploits which rely on overflowing into neighboring objects or require object at specific alignment in a slab lose reliability. Heap spray can be used to counteract this.
CONFIG_SLAB_FREELIST_HARDENED
This config option requires the SLUB allocator. It encrypts the inline freelist pointers present in freed objects with a random 8 byte value, generated at runtime. The encryption is a basic bitwise xor operation. This prevents information leak and hijacking the freelist. It can be bypassed by getting a heap leak and an encrypted pointer leak and xoring both to get the encryption key.
CONFIG_MEMCG_KMEM
Although strictly not a hardening config option, it makes exploitation ever so harder. This causes some commonly used objects, to be put in kmalloc-cg-x caches instead of the usual kmalloc-x caches. This is because these objects are allocated with the flag SLAB_ACCOUNT. This can be overcome using cross-cache.
CONFIG_RANDOM_KMALLOC_CACHES
This config option creates multiple copies of kmalloc-cg-x and kmalloc-x caches. The copy of the cache chosen for allocation, depends on a random seed and the return address for kmalloc(). This reduces exploit reliability a lot. However cross-cache can be used to overcome this.
CONFIG_SLAB_VIRTUAL
This config option still hasn’t been merged with mainline yet. It aims to prevent cross-cache and UAFs in general by preventing re-use of the same virtual address for a slab across different caches. After looking at a bunch of _mitigation exploits for kernelctf, I don’t see any bypasses for this yet. Please correct me if I’m wrong.
Objects
You can use tools such as pahole and kernel_obj_finder to get objects available in the build you’re working with.
Elastic objects
These objects are called so, because they can be allocated in various general purpose caches. Although the introduction of CONFIG_MEMCG_KMEM, moved most of them to the kmalloc-cg-x caches. These objects are useful because of their dynamic size and user controlled content.
struct msg_msg- allocate:
msgsnd() - free:
msgrcv() - size:
0x40 - 0x1000
- allocate:
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security;
/* the actual message follows immediately */
};
struct msg_msgseg- allocated and freed using same path as
msg_msg - allocation occurs when msg datalen > 0xfc8
- the remaining bytes are put in a
struct msg_msgseg - size:
0x10-0x1000
- allocated and freed using same path as
struct msg_msgseg {
struct msg_msgseg *next;
/* the next part of the message follows immediately */
};
struct simple_xattr- allocate:
setxattr()on atmpfsfilesystem - free:
removexattr() - size:
0x30 - ?
- allocate:
struct simple_xattr {
struct rb_node rb_node;
char *name;
size_t size;
char value[];
};
struct user_key_payload- allocate:
add_key() - free:
keyctl_revoke()+keyctl_unlink() - size:
0x20 - ?
- allocate:
struct user_key_payload {
struct rcu_head rcu;
unsigned short datalen;
char data[] __aligned(__alignof__(u64));
}
Critical objects
Being able to overwrite or control these objects usually leads to privilege escalation. These objects usually contain flags that control permissions. Since they are critical, they are usually allocated in dedicated caches with SLAB_NOMERGE, SLAB_ACCOUNT flags.
struct cred- private cache:
cred_jar - allocate:
fork(),clone() - free:
exit() - size:
0xa0 - overwrite
uid,gidmembers for changing privileges of process
- private cache:
struct file- private cache:
files_cache - allocate:
open() - free:
close() - size:
0x300 - overwrite
f_modeto change file access permissions
- private cache:
Some simple challenges
- Pawnyable (heap overflow, UAF)
- CISCN2017 - baby driver (UAF)
- CUCTF2019 - hotrod (userfaultfd race + UAF)
- bi0sCTF2022 - k32 (heap overflow) (shameless plug :D)
- backdoorCTF2023 - empdb (userfaultfd race + freelist poisoning)
The end
I started writing this for my reference in the future, but it turned into a blog post. I will probably update this few times until I’m satisfied with it. I would like to thank a few people, for motivating and helping me with learning Linux Kernel Exploitation: Cyb0rG, 3agl3 & kylebot